How GetAI scores models without earning your distrust.
Every choice below is documented in the Spectra change log. What is live today is stated as live. What is planned is stated as planned. No aspirational language from a blueprint is treated as a current feature.
What is actually running today.
GetAI is in its initial public-evaluation phase. What you see on the leaderboard is the real current state of the pipeline — not a planned future specification. The counts below are facts, not targets.
judge: Gemini 2.5 Flash via OpenRouter · pack: tw-ai-thinking-v1 · full run every Sunday 10:00 UTC
loading live counts from /api/leaderboard…
Public roadmap · what is planned but not yet built
Every item below is tracked in the Spectra change log and ships only when it is ready. Dates are intent, not commitment.
| When | Item | Status |
|---|---|---|
| Week 1 | Honest homepage + methodology + cryptographic verifiability callout | in progress |
| Week 2 | Candidate roster expands from 7 to 11 (Nvidia NIM free tier × 10 open-weight models) | queued |
| Week 3 | Silent-update drift detection wired into each weekly run; incident template ready | queued |
| Week 4 | Community support button + first Traditional-Chinese vertical pack (invoice ops) | queued |
| Later | Second judge, closed-flagship candidates, routing advisor, private-pack distillation for enterprise | unscheduled |
The eight core axes
Every trial is scored along the same eight dimensions. Track-specific axes (efficiency, recovery, refusal appropriateness, tool-use efficacy, plan coherence, locale fidelity) attach when a pack opts into a given track.
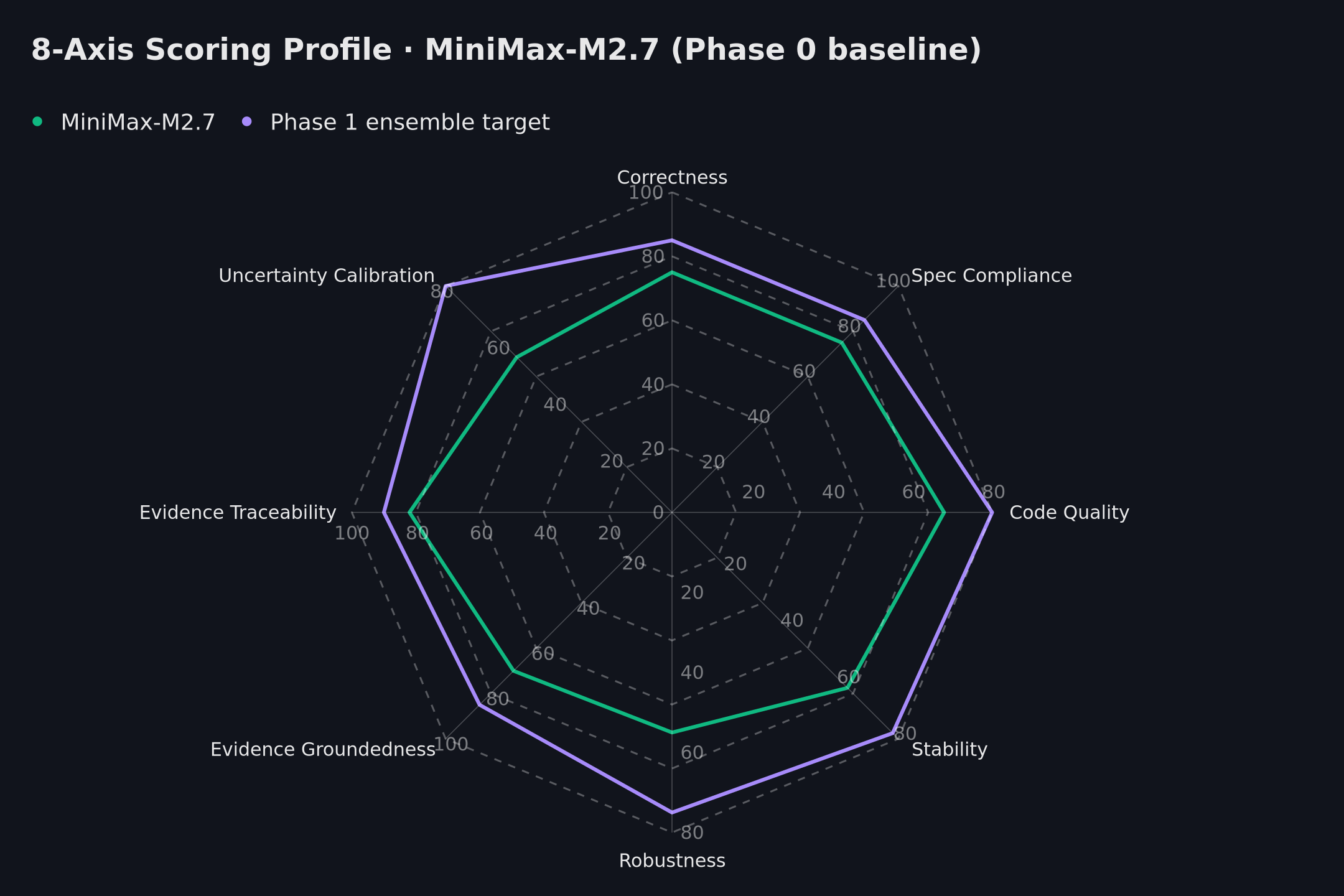
8-axis profile
The radar below shows the current Phase 0 profile across the eight core axes, computed from the live weekly run. All shapes use the same axis weights — no normalisation tricks.
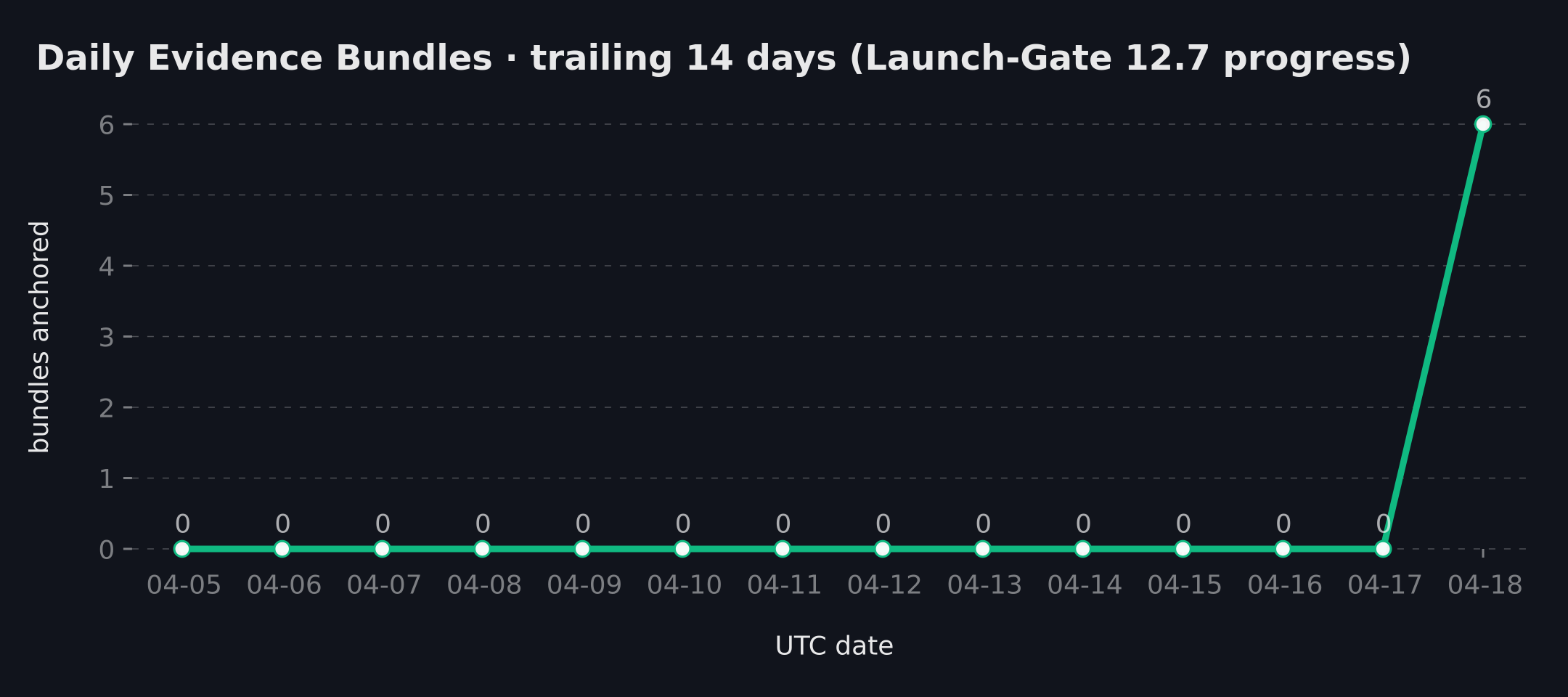
Daily anchor activity · 14-day window
Each day a daily-anchor workflow publishes a Merkle root over every evidence bundle produced in that window. Consecutive days of published roots build the public-verifiability streak shown on the homepage.
Judge configuration · single judge, by design
A single judge (Gemini 2.5 Flash, via OpenRouter) scores every trial. This is deliberately a single judge, not an ensemble. Every score produced under this configuration carries a provisional=true marker, and the leaderboard is presented as a directional signal, not a final ranking.
- Why a single judge today: adding a second closed-model judge (for example Claude Sonnet or GPT-5) raises judge cost from roughly US$1/month to US$50/month. GetAI currently has zero paying customers, zero donors, and zero enterprise inquiries — that upgrade is not yet justified.
- How we compensate: every score is explicitly flagged provisional; the homepage states the single-judge configuration in plain language; the ranking is framed as "relative signal, not final truth."
- When this changes: a second judge is added the moment GetAI reaches its first paying-customer signal — a subscription, a donation of US$5 or more, or a qualified enterprise inquiry. At that point the
provisionalflag is partially lifted. - Long-term target: a 3-judge heterogeneous ensemble (n ≥ 3, ≥ 2 vendor families, continuous Krippendorff α measurement). That ensemble is on the roadmap, not pretended to exist today.
Drift detection
Per-axis drift is monitored with a four-stack:
| Stack | Purpose | Tunable |
|---|---|---|
| MAD-z | Outlier flag | z > 3.5 |
| CUSUM | Sustained shift | k = 0.5σ, h = 5σ |
| Page-Hinkley | Change-point | λ = 50 |
| Mann-Whitney U + BH | Distribution test + FDR control | monthly FP < 0.5% |
Silent update probe (D5)
Vendors swap models without telling you. GetAI catches it via 2-of-3 signal fusion:
- S1 — header hash: SHA-256 over canonicalised response headers (CDN noise stripped).
- S2 — fingerprint cosine: embeddings of model self-identification responses; threshold 0.08.
- S3 — vendor notes scraper: changelog + release notes parsing.
Two of three must trigger to raise an incident. Single-signal trips are queued for review but never auto-published.
Evidence chain
Each trial produces a content-addressable Evidence Bundle:
- manifest.json — canonical orjson, sorted keys, naive UTC
- {inputs,outputs,tool_events,judge_verdicts,scores}.ndjson
- SIGNATURES.json — SHA-256 of manifest, optional vendor sigs
- merkle_proof.json — leaf hash + sibling path + root
- attribution.json — phase, judge_mode, comparability marker
Non-goals (Codex-pruned)
- Carbon estimation, public hash-chain ledger, DOI/academic tier
- Live replay UI, DAO marketplace, long-context-only track
- Auto-routing bandit, three-region deployment, full SOC 2 in v1
- Legal / medical content generation
- A single universal "AI score" — every score has a context
"Build the AI regression system that survives a procurement review — and publishes its proofs week after week, so anyone can audit them."